[NMDL] Tản mạn về việc tăng độ lớn của mô hình.
Chúc độc giả năm mới vui vẻ và như ý.
Thách thức
Sau khi đã biết qua về Fully Connected Layer và CNN, chúng ta dần đi vào một quỹ đạo của việc thiết kế các mô hình học sâu với số lớp ngày càng tăng (có thể lên tới hàng trăm). Có rất nhiều lý do để khiến cho việc tăng độ sâu này trở lên hữu ích. Lấy ví dụ như receptive field của mạng CNN sẽ tăng dần qua mỗi lớp CNN, tức là một feature ở lớp sau có thể biểu diễn (dại diện) cho thông tin của nhiều pixel hơn so với feature ở lớp trước. Tuy nhiên, tăng độ sâu cho mô hình cũng kéo theo nhiều vấn đề cần phải giải quyết. Lấy ví dụ như:
Overfitting (học vẹt):
Điều này tương tự như hiện tượng overfitting trong máy học. Mô hình đã học quá kỹ dữ liệu huấn luyện đến nỗi nó trở nên quá nhạy cảm với những nhiễu, biến động nhỏ trong dữ liệu mới. Mô hình đã “học vẹt” dữ liệu huấn luyện thay vì học được những đặc trưng chung của các loại trái cây.
Chi phí tính toán
Bộ nhớ: Các mô hình lớn cần một lượng bộ nhớ lớn để lưu trữ các tham số và dữ liệu trung gian.
Thời gian: Quá trình huấn luyện các mô hình lớn có thể kéo dài hàng ngày, thậm chí hàng tuần.
Tính toán: Các phép tính số học phức tạp cần được thực hiện hàng tỷ lần.
Thời gian: Quá trình huấn luyện các mô hình lớn có thể kéo dài hàng ngày, thậm chí hàng tuần.
Tính toán: Các phép tính số học phức tạp cần được thực hiện hàng tỷ lần.
Các thách thức cụ thể:
– Kích thước mô hình: Số lượng tham số trong mô hình càng lớn, yêu cầu về bộ nhớ và thời gian tính toán càng cao.
– Lượng dữ liệu: Để huấn luyện các mô hình lớn, chúng ta cần một lượng dữ liệu khổng lồ. Việc xử lý và truyền dữ liệu này cũng tiêu tốn rất nhiều tài nguyên.
– Độ phức tạp của thuật toán: Các thuật toán tối ưu hóa phức tạp như SGD (Stochastic Gradient Descent) cần nhiều lần lặp để tìm ra giá trị tối ưu của các tham số.
– Lượng dữ liệu: Để huấn luyện các mô hình lớn, chúng ta cần một lượng dữ liệu khổng lồ. Việc xử lý và truyền dữ liệu này cũng tiêu tốn rất nhiều tài nguyên.
– Độ phức tạp của thuật toán: Các thuật toán tối ưu hóa phức tạp như SGD (Stochastic Gradient Descent) cần nhiều lần lặp để tìm ra giá trị tối ưu của các tham số.
Các mô hình lớn có nhiều tham số hơn, điều này đồng nghĩa với việc chúng có khả năng biểu diễn thông tin phức tạp hơn. Tuy nhiên, để các mô hình này hoạt động tốt, chúng cần được huấn luyện trên một lượng dữ liệu đủ lớn để tránh overfitting.
Tránh overfitting: Với nhiều tham số, mô hình dễ dàng “học thuộc lòng” dữ liệu huấn luyện, dẫn đến việc không thể generalise tốt trên dữ liệu mới.
Bắt chước các phân bố: Mô hình cần học được phân bố xác suất của dữ liệu. Với một lượng dữ liệu lớn, mô hình có thể bắt chước chính xác hơn phân bố này.
Khám phá các đặc trưng phức tạp: Các mô hình lớn có khả năng khám phá những đặc trưng phức tạp, ẩn sâu trong dữ liệu. Tuy nhiên, để làm được điều này, chúng cần được cung cấp một lượng dữ liệu đủ lớn.
Bắt chước các phân bố: Mô hình cần học được phân bố xác suất của dữ liệu. Với một lượng dữ liệu lớn, mô hình có thể bắt chước chính xác hơn phân bố này.
Khám phá các đặc trưng phức tạp: Các mô hình lớn có khả năng khám phá những đặc trưng phức tạp, ẩn sâu trong dữ liệu. Tuy nhiên, để làm được điều này, chúng cần được cung cấp một lượng dữ liệu đủ lớn.
Tản mạn về ImageNet Challenge
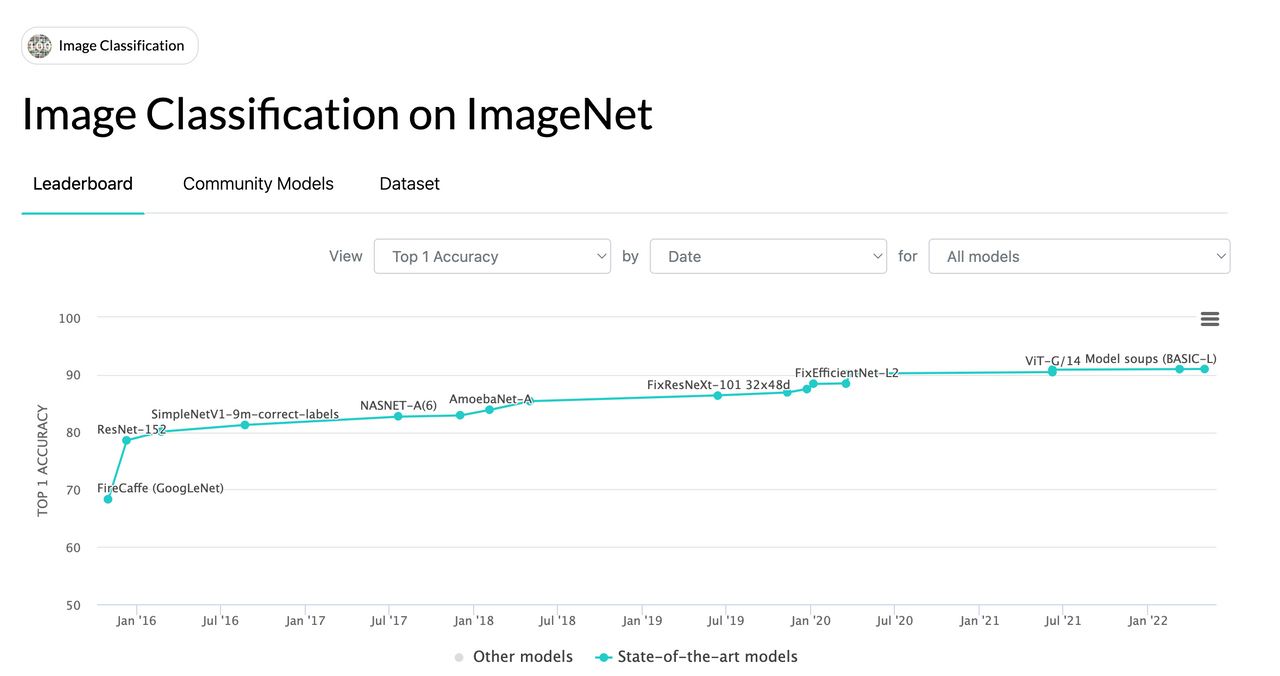
Ở phần trước, tôi đã trình bày một ví dụ mà ở đó mô hình được yêu cầu phân loại hình ảnh theo các nhãn. Đây là bài toán phân loại hình ảnh (image classification). Bài toán này vốn thu hút rất nhiều sự quan tâm của cộng đồng nghiên cứu học thuật thời 2012-2018 với những cái tên máu mặt như Geofrey Hilton, Li Fei Fei, etc. Và làm lên tên tuổi hoặc bước đệm cho những trụ cột của AI trong thời đại hiện tại, lấy vị dụ như Ilya Sutskever (co-founded and is a former chief scientist at OpenAI). Hầu hết sự phát triển trong thời đại này có sự tham gia của thử thách ImageNet (ImageNet challenge) hoặc tên đầy đủ là ImageNet Large Scale Visual Recognition Challenge. Challenge này được tổ chức hàng năm để thi đấu giữa các mô hình xem đâu là SOTA (state-of-the-art) trong bài toán image classification. Phần data được dùng là một tập con của tập ImageNet, với khoảng 1M (1 triệu) ảnh có gắn nhãn (tag), và có 1K (1000) nhãn tổng cộng.
Tuy nhiên, mọi chuyện không chỉ giới hạn ở việc cứ vậy mà tăng số lớp, số tham số, số liên kết lên để đạt được mô hình tốt hơn. Nói đơn giản như việc thêm một vài lớp CNN vào mô hình cũng có thể là một vấn đề không tầm thường khi mà có thể gặp phải hàng tá vấn đề có thể xảy đến. Ví dụ kể đến được như là tối ưu chậm (slow optimization), vấn đề về gradients, hoặc là sự bất ổn số học (numerical instabilities). Hoặc những bí ẩn trời ơi đất hỡi như là mô hình đột nhiên bị huỷ trong quá trình huấn luyện (được đề cập trong một bài nói của Yu Zhang hé lộ trong quá trình huấn luyện GPT-4o)
*Top-5% error đơn giản là một cách đo lường hiệu suất của các mô hình phân loại hình ảnh. Cụ thể, nó chỉ ra tỷ lệ các hình ảnh mà mô hình dự đoán sai trong top 5 lựa chọn hàng đầu.
Vì viết đến lưng chừng, mà dài quá thì không ai đọc, nên tôi tạm dừng ở đây. Kết thúc một cái tản mạn nhẹ nhàng cho đầu năm mới. Trong các phần tiếp theo, tôi sẽ giới thiệu sơ qua các kỹ thuật vừa kể trên. Sẽ có một chút toán trở lại.
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012).
[2] Yu, Jiahui, et al. “Coca: Contrastive captioners are image-text foundation models.” arXiv preprint arXiv:2205.01917 (2022).
[3] Abacha, Asma Ben, et al. “Medec: A benchmark for medical error detection and correction in clinical notes.” arXiv preprint arXiv:2412.19260 (2024).
[4] Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
[2] Yu, Jiahui, et al. “Coca: Contrastive captioners are image-text foundation models.” arXiv preprint arXiv:2205.01917 (2022).
[3] Abacha, Asma Ben, et al. “Medec: A benchmark for medical error detection and correction in clinical notes.” arXiv preprint arXiv:2412.19260 (2024).
[4] Kaplan, Jared, et al. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).

